日刊競馬の予想印をもとに、競馬予想を行うベストな方法の結果です。前回は、2010年3月28日(日)の新聞にのった予想印の予想精度を、ARという指標で評価してみました。たった、18レースだったこともあり、オッズよりも精度が高い予想者の方もいて、すこし驚きました。私の想定では、オッズの精度がもっともよく、専門家の予想精度はそれに劣るはずだったからです。ただ、ARをもとに精度の比較を行うなら、最低50レースは必要。クレジットリスクの論文では、最低50のデフォルトがないと、比較できない、とあるので、競馬の場合なら50頭の勝ち馬=50レースとなるわけです。そこで、まず、データを2010年3月27日(土)から2010年4月11日(日)までの、土日6日分。レース数にして96レースのデータを作りました。日刊競馬のサイトでは、過去記事のpdfファイルを200円で販売していて、それを利用。本命1、対抗2から無印を6と番号を振り、あと意味不明は星印は7としています。それをJRA-VANのレースコードを振り、レースコード、馬番号、着順、6名の記者予想、オッズの10列のデータとしました。前回の一日分のデータでは、予想者が異なるレースが2レース含まれていたので、今回は、その点も注意して
データ化しています。
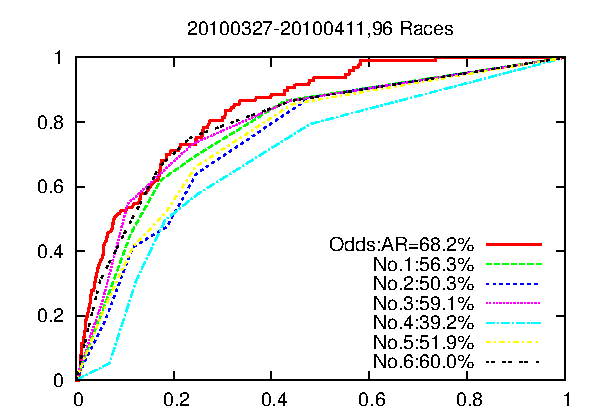
まずは、6名の記者予想と、オッズのARの比較です。6名の予想者それぞれの予想のARは、56.3%(柏木)、50.3%(宮崎)、59.1%(黒津)、39.2%(久保木)、51.9%(桧原)、60.0%(本誌飯田)。一方、オッズの予想精度は、68.2%となり、私の想定通り、オッズの精度が最高で、専門家の予想はそれに劣ることがわかります。
では、前回の課題の結果です。課題は、予想印の点を、本命1、対抗2、穴馬3とするのではなく、ARが最大になるように決めるというものでした。さらに、6名の記者の予想の混ぜ方の比率を変える、や、オッズの数値も点数として混ぜるなど、いろいろな条件でARを最大化することが考えられます。この場合、ARは、こうした点数や混ぜ方の関数となります。予想印だけを考える場合、本命の点を1に固定すると、そのあと対抗から無印までの5個の点(星印はよくわからないので、無印として扱いました)の関数、つまり5変数関数となります。さらに、6名の記者の混ぜ方を考えると、6個の比率という変数が加わりますが、比率の和は1なので、実質的には5個の追加となり、10変数関数ということになります。さらにオッズが加わると、その重みも入り11変数関数となります。
こうした多変数関数を最大化するには、通常「最速降下法」など、関数のそれぞれの変数方向の傾きの情報を使って、変数の値を徐々に変えていくのですが、それには傾き=微分を計算しないといけない。普通の多変数関数の場合、微分を適当に差分で置き換えてやればいいのですが、ARの場合は、そう簡単ではありません。ARはもともと、序列の完成度を数値化したものなので、パラメータの微小な変化に対して、変化せず、微分が計算できないのです。例えば、対抗の馬の点を2から2.001に変えても、ARが変わらないと予想できます。
そこで、ここでは「焼きなまし法」という手法を用いることにします。これは、微分の情報を使わず、変数を少し変えたときの、ARの変化をもとに、その変数の変化を採用するかどうかを確率的に決めることに基づいた手法で、もともとは統計物理学で生まれた手法です。その詳細は、Wikipediaなどに任せるとして、その結果だけ示すことにします。
三つのケースを考えています。ひとつは、前回も述べた、得点は1,2,3,4,5,6で、6名の予想を平均したもの(Model1)。次は、点を変えたもの(Model2)。最後は、6名の予想者の比率をARが最大になるように変えたもの(Model3)。まず、単純な平均では、ARは65.1%で、6名の予想のARが39.2%から60.0%だったことを考えると、その予想精度を5%も向上させていることがわかります。一方、点を変えた場合、ARは65.8%で、単純な点のModel1からのパフォーマンスの向上は0.7%で1%を切っています。最後のModel3では、6名の予想をうまく混ぜてARを最大化したのでオッズよりもARが大きくなっています。
では、このModel3を使えば、オッズよりも優秀な競馬予想が可能なのでしょうか?もちろん、そうではありません。この結果は、単に勝ち負けの結果をもとに、ARが最大になる組み合わせを決めただけであって、それは本当に精度が高いかどうかは、別のデータで検証する必要があります。そこで、次回は、次の3週分(4月17日から5月2日)のデータをもとに、このModel3の予想精度を検証してみましょう。
卒研の課題:ARを最大化するプログラムを書き、上記の結果を再現せよ。とりあえず、Model2なら、焼きなまし法でなくても、For ループを5回やれば出来ます。頭のいい方法ではもちろんありません。次の土曜日に、焼きなまし法の解説をします。