Role of parties in the vote distribution of proportional elections
L.E. Araripe, R.N. Costa Filho,Physica A 388 (2009) 4167–4170
ブラジル(1998,2002,2006)およびフィンランド(2003)の比例代表制選挙の得票率の分布を調べた論文。過去の研究ではブラジル、インドでは票数の分布がカットオフのあるべき分布ということが知られている。データはオンラインで公開[9][10]
解析結果は、得票率の分布は指数1のべき分布。得票率vの候補者数N(v)はvが1/1000か1/10のレンジで1/vで振る舞う。
この論文では政党お分布への影響を調べるために、政党毎の平均得票率v0を求め、v/v0の分布を調べた。v/v0=1の近くではデータは似た振る舞いをするが、ブラジルは指数分布でピークがなく、フィンランドは対数正規分布でv/v0=0.15にピークを持つ。このように、スケール不変性、普遍性が失われた。
2017年11月10日金曜日
備忘録:A spatial analysis of county-level outcomes in US Presidential elections:1988-2000
A spatial analysis of county-level outcomes in US Presidential elections: 1988–2000
Jeongdai Kim, Euel Elliott, Ding-Ming Wang,Electoral Studies 22 (2003) 741–761.
アメリカの大統領選挙の4回分のcountyレベルデータ(1988-2000)を用いて民主、共和党の得票率の空間パターンを明らかにした。空間パターンとして、境界を接するcounty間をつなぐ場合と、通勤データで5%以上の率を占めるcounty間をつなぐ場合とを考える。空間パターンを計測するために、都市部からの民主、共和への得票率の変化を調べ、民主が高いというurban biasを確認した。1988年では差は1.9%だが、2000年では8.9%になっている。また、MoranのIという、隣接するcounyの得票率をcountyの得票率で線形回帰したときの回帰係数を求め、1988年の0.5から2000年の0.6まで上昇していることを示した。MoranのIをcounty毎に計算したときのLocal Moran's Iを求め、countyと隣接countyのMoran's Iが高ー高(HH)、低ー低(LL)などのパターンの空間分布を調べたところ、民主がHHだと共和はLL、逆も真(例外は1992のペロー候補のときだが、1996には消滅)。東部と都市部は民主、西部は共和というパターンが確認できた。境界はミシシッピ川(ミネソタからルイジアナ)。この傾向は西部22州、東部27州でのHH,LLでの得票率の変化からも確認できる。
また、各countyの共和、民主の得票数をcountyの人口、失業率、所得で回帰するモデル(issue-priority model)を導入し、失業率が民主党の得票数を説明すること示した。ただし、90年代に入ると、回帰係数は小さくなり2000年では有意ではない。二期目の政権の得票数に対する回帰モデル(reward-punishment model)については、データが少ないため結論が出せない。
Jeongdai Kim, Euel Elliott, Ding-Ming Wang,Electoral Studies 22 (2003) 741–761.
アメリカの大統領選挙の4回分のcountyレベルデータ(1988-2000)を用いて民主、共和党の得票率の空間パターンを明らかにした。空間パターンとして、境界を接するcounty間をつなぐ場合と、通勤データで5%以上の率を占めるcounty間をつなぐ場合とを考える。空間パターンを計測するために、都市部からの民主、共和への得票率の変化を調べ、民主が高いというurban biasを確認した。1988年では差は1.9%だが、2000年では8.9%になっている。また、MoranのIという、隣接するcounyの得票率をcountyの得票率で線形回帰したときの回帰係数を求め、1988年の0.5から2000年の0.6まで上昇していることを示した。MoranのIをcounty毎に計算したときのLocal Moran's Iを求め、countyと隣接countyのMoran's Iが高ー高(HH)、低ー低(LL)などのパターンの空間分布を調べたところ、民主がHHだと共和はLL、逆も真(例外は1992のペロー候補のときだが、1996には消滅)。東部と都市部は民主、西部は共和というパターンが確認できた。境界はミシシッピ川(ミネソタからルイジアナ)。この傾向は西部22州、東部27州でのHH,LLでの得票率の変化からも確認できる。
また、各countyの共和、民主の得票数をcountyの人口、失業率、所得で回帰するモデル(issue-priority model)を導入し、失業率が民主党の得票数を説明すること示した。ただし、90年代に入ると、回帰係数は小さくなり2000年では有意ではない。二期目の政権の得票数に対する回帰モデル(reward-punishment model)については、データが少ないため結論が出せない。
2012年4月24日火曜日
競馬予想の精度4
前回は、日刊競馬の6名の予想をもとに、もっとも精度の高い競馬予想を行う方法として、精度(ここではAR=Accuarcy Ratioを用いています)が最大になるような手法を考えました。ただ、あるレースデータをもとにARを最大化しても、それを額面どおりに受け取ることはできません。では、どうするのかというと、ARの最大化に用いたレースデータとは別のレースデータを用意し、それでARを計算して比較します。つまり、学習データとパフォーマンスを計測するデータを別にするわけです。
そこで、学習データとして2010年3月27日から4月25日までの160レース2311頭のデータを用い、パフォーマンスの計算には、2010年5月1日から9日までの64レース927頭のデータを用いることにします。用いたデータは、以下のものです。
まず、学習データで、ARを最大化するポイント(本命、対抗などにつける点)を最大化すると、1:1: 1.4:1.9:2.4:2.9となり、ARは65.6%。ちなみに、前回述べたポイントが1:2:3:4:5:6の場合のARは65.1%なので、ARが大きくなるようにポイントが選ばれていることが分かります。以下、1:2:3:4:5:6のモデルをモデル0、ARを最大化したモデルをモデル1と呼ぶことにしましょう。問題は、モデル1がモデル0より予想精度が高くなっているのかどうかです。そこで、5月1日からの64レースのデータでARを比較してみることにします。
モデル0とモデル1でパフォーマンス比較を行ったときのROCカーブが下の図です。ARは、モデル0が61.0%、モデル1が60.5%となり、64レースとレース数が少ないので、確実に劣る(ARの差が優位)とまでは断言できませんが、すくなくともパフォーマンスが良くなってはいないことが分かります。
つまり、ARを最大化するようにポイントを動かした結果は過学習であって、新たなレースでの予測には使えないことが分かります。ちなみに、オッズのARは69.3%、6名の予想のARはそれぞれ44.6%,41.1%,46.5%,44.2%,55.0%,55.7%で、6名の平均のモデル0の精度が記者予想を5%以上上回っていることが分かります。
 しかし、オッズの予想精度には8%以上負けているわけで、この差を埋める、さらにはオッズに勝つにはどうすればいいのでしょう?この答えを求めるのが目標であり、そう簡単ではありません。そこで、競馬予想の精度をあげることを考える前に、すこし競馬予想の別の観点からの比較を行ってみることにしましょう。
しかし、オッズの予想精度には8%以上負けているわけで、この差を埋める、さらにはオッズに勝つにはどうすればいいのでしょう?この答えを求めるのが目標であり、そう簡単ではありません。そこで、競馬予想の精度をあげることを考える前に、すこし競馬予想の別の観点からの比較を行ってみることにしましょう。
そこで、学習データとして2010年3月27日から4月25日までの160レース2311頭のデータを用い、パフォーマンスの計算には、2010年5月1日から9日までの64レース927頭のデータを用いることにします。用いたデータは、以下のものです。
まず、学習データで、ARを最大化するポイント(本命、対抗などにつける点)を最大化すると、1:1: 1.4:1.9:2.4:2.9となり、ARは65.6%。ちなみに、前回述べたポイントが1:2:3:4:5:6の場合のARは65.1%なので、ARが大きくなるようにポイントが選ばれていることが分かります。以下、1:2:3:4:5:6のモデルをモデル0、ARを最大化したモデルをモデル1と呼ぶことにしましょう。問題は、モデル1がモデル0より予想精度が高くなっているのかどうかです。そこで、5月1日からの64レースのデータでARを比較してみることにします。
モデル0とモデル1でパフォーマンス比較を行ったときのROCカーブが下の図です。ARは、モデル0が61.0%、モデル1が60.5%となり、64レースとレース数が少ないので、確実に劣る(ARの差が優位)とまでは断言できませんが、すくなくともパフォーマンスが良くなってはいないことが分かります。
つまり、ARを最大化するようにポイントを動かした結果は過学習であって、新たなレースでの予測には使えないことが分かります。ちなみに、オッズのARは69.3%、6名の予想のARはそれぞれ44.6%,41.1%,46.5%,44.2%,55.0%,55.7%で、6名の平均のモデル0の精度が記者予想を5%以上上回っていることが分かります。

2012年4月15日日曜日
競馬予想の精度3
日刊競馬の予想印をもとに、競馬予想を行うベストな方法の結果です。前回は、2010年3月28日(日)の新聞にのった予想印の予想精度を、ARという指標で評価してみました。たった、18レースだったこともあり、オッズよりも精度が高い予想者の方もいて、すこし驚きました。私の想定では、オッズの精度がもっともよく、専門家の予想精度はそれに劣るはずだったからです。ただ、ARをもとに精度の比較を行うなら、最低50レースは必要。クレジットリスクの論文では、最低50のデフォルトがないと、比較できない、とあるので、競馬の場合なら50頭の勝ち馬=50レースとなるわけです。そこで、まず、データを2010年3月27日(土)から2010年4月11日(日)までの、土日6日分。レース数にして96レースのデータを作りました。日刊競馬のサイトでは、過去記事のpdfファイルを200円で販売していて、それを利用。本命1、対抗2から無印を6と番号を振り、あと意味不明は星印は7としています。それをJRA-VANのレースコードを振り、レースコード、馬番号、着順、6名の記者予想、オッズの10列のデータとしました。前回の一日分のデータでは、予想者が異なるレースが2レース含まれていたので、今回は、その点も注意してデータ化しています。

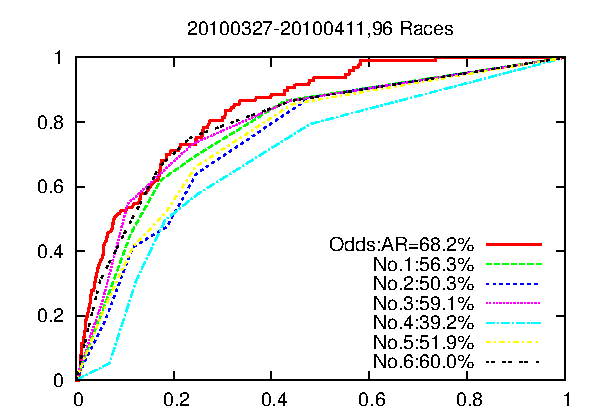
まずは、6名の記者予想と、オッズのARの比較です。6名の予想者それぞれの予想のARは、56.3%(柏木)、50.3%(宮崎)、59.1%(黒津)、39.2%(久保木)、51.9%(桧原)、60.0%(本誌飯田)。一方、オッズの予想精度は、68.2%となり、私の想定通り、オッズの精度が最高で、専門家の予想はそれに劣ることがわかります。
では、前回の課題の結果です。課題は、予想印の点を、本命1、対抗2、穴馬3とするのではなく、ARが最大になるように決めるというものでした。さらに、6名の記者の予想の混ぜ方の比率を変える、や、オッズの数値も点数として混ぜるなど、いろいろな条件でARを最大化することが考えられます。この場合、ARは、こうした点数や混ぜ方の関数となります。予想印だけを考える場合、本命の点を1に固定すると、そのあと対抗から無印までの5個の点(星印はよくわからないので、無印として扱いました)の関数、つまり5変数関数となります。さらに、6名の記者の混ぜ方を考えると、6個の比率という変数が加わりますが、比率の和は1なので、実質的には5個の追加となり、10変数関数ということになります。さらにオッズが加わると、その重みも入り11変数関数となります。
こうした多変数関数を最大化するには、通常「最速降下法」など、関数のそれぞれの変数方向の傾きの情報を使って、変数の値を徐々に変えていくのですが、それには傾き=微分を計算しないといけない。普通の多変数関数の場合、微分を適当に差分で置き換えてやればいいのですが、ARの場合は、そう簡単ではありません。ARはもともと、序列の完成度を数値化したものなので、パラメータの微小な変化に対して、変化せず、微分が計算できないのです。例えば、対抗の馬の点を2から2.001に変えても、ARが変わらないと予想できます。
そこで、ここでは「焼きなまし法」という手法を用いることにします。これは、微分の情報を使わず、変数を少し変えたときの、ARの変化をもとに、その変数の変化を採用するかどうかを確率的に決めることに基づいた手法で、もともとは統計物理学で生まれた手法です。その詳細は、Wikipediaなどに任せるとして、その結果だけ示すことにします。

三つのケースを考えています。ひとつは、前回も述べた、得点は1,2,3,4,5,6で、6名の予想を平均したもの(Model1)。次は、点を変えたもの(Model2)。最後は、6名の予想者の比率をARが最大になるように変えたもの(Model3)。まず、単純な平均では、ARは65.1%で、6名の予想のARが39.2%から60.0%だったことを考えると、その予想精度を5%も向上させていることがわかります。一方、点を変えた場合、ARは65.8%で、単純な点のModel1からのパフォーマンスの向上は0.7%で1%を切っています。最後のModel3では、6名の予想をうまく混ぜてARを最大化したのでオッズよりもARが大きくなっています。
では、このModel3を使えば、オッズよりも優秀な競馬予想が可能なのでしょうか?もちろん、そうではありません。この結果は、単に勝ち負けの結果をもとに、ARが最大になる組み合わせを決めただけであって、それは本当に精度が高いかどうかは、別のデータで検証する必要があります。そこで、次回は、次の3週分(4月17日から5月2日)のデータをもとに、このModel3の予想精度を検証してみましょう。
卒研の課題:ARを最大化するプログラムを書き、上記の結果を再現せよ。とりあえず、Model2なら、焼きなまし法でなくても、For ループを5回やれば出来ます。頭のいい方法ではもちろんありません。次の土曜日に、焼きなまし法の解説をします。
まずは、6名の記者予想と、オッズのARの比較です。6名の予想者それぞれの予想のARは、56.3%(柏木)、50.3%(宮崎)、59.1%(黒津)、39.2%(久保木)、51.9%(桧原)、60.0%(本誌飯田)。一方、オッズの予想精度は、68.2%となり、私の想定通り、オッズの精度が最高で、専門家の予想はそれに劣ることがわかります。
では、前回の課題の結果です。課題は、予想印の点を、本命1、対抗2、穴馬3とするのではなく、ARが最大になるように決めるというものでした。さらに、6名の記者の予想の混ぜ方の比率を変える、や、オッズの数値も点数として混ぜるなど、いろいろな条件でARを最大化することが考えられます。この場合、ARは、こうした点数や混ぜ方の関数となります。予想印だけを考える場合、本命の点を1に固定すると、そのあと対抗から無印までの5個の点(星印はよくわからないので、無印として扱いました)の関数、つまり5変数関数となります。さらに、6名の記者の混ぜ方を考えると、6個の比率という変数が加わりますが、比率の和は1なので、実質的には5個の追加となり、10変数関数ということになります。さらにオッズが加わると、その重みも入り11変数関数となります。
こうした多変数関数を最大化するには、通常「最速降下法」など、関数のそれぞれの変数方向の傾きの情報を使って、変数の値を徐々に変えていくのですが、それには傾き=微分を計算しないといけない。普通の多変数関数の場合、微分を適当に差分で置き換えてやればいいのですが、ARの場合は、そう簡単ではありません。ARはもともと、序列の完成度を数値化したものなので、パラメータの微小な変化に対して、変化せず、微分が計算できないのです。例えば、対抗の馬の点を2から2.001に変えても、ARが変わらないと予想できます。
そこで、ここでは「焼きなまし法」という手法を用いることにします。これは、微分の情報を使わず、変数を少し変えたときの、ARの変化をもとに、その変数の変化を採用するかどうかを確率的に決めることに基づいた手法で、もともとは統計物理学で生まれた手法です。その詳細は、Wikipediaなどに任せるとして、その結果だけ示すことにします。

三つのケースを考えています。ひとつは、前回も述べた、得点は1,2,3,4,5,6で、6名の予想を平均したもの(Model1)。次は、点を変えたもの(Model2)。最後は、6名の予想者の比率をARが最大になるように変えたもの(Model3)。まず、単純な平均では、ARは65.1%で、6名の予想のARが39.2%から60.0%だったことを考えると、その予想精度を5%も向上させていることがわかります。一方、点を変えた場合、ARは65.8%で、単純な点のModel1からのパフォーマンスの向上は0.7%で1%を切っています。最後のModel3では、6名の予想をうまく混ぜてARを最大化したのでオッズよりもARが大きくなっています。
では、このModel3を使えば、オッズよりも優秀な競馬予想が可能なのでしょうか?もちろん、そうではありません。この結果は、単に勝ち負けの結果をもとに、ARが最大になる組み合わせを決めただけであって、それは本当に精度が高いかどうかは、別のデータで検証する必要があります。そこで、次回は、次の3週分(4月17日から5月2日)のデータをもとに、このModel3の予想精度を検証してみましょう。
卒研の課題:ARを最大化するプログラムを書き、上記の結果を再現せよ。とりあえず、Model2なら、焼きなまし法でなくても、For ループを5回やれば出来ます。頭のいい方法ではもちろんありません。次の土曜日に、焼きなまし法の解説をします。
2012年3月20日火曜日
競馬予想の精度2
前回の課題の結果です。
課題のデータは、全部で18レース分です。
(本命1、対抗2、 単穴3、二重△4、△5、その他6としています。勝馬1、負け馬0。)
http://dl.dropbox.com/u/13984080/20120303_kadai.d
このデータを用いて、6名の予想者それぞれのARを計算するというものでした。結果は、6名の予想者それぞれの予想のARは、77.6%(柏木)、50.7%(宮崎)、60.4%(黒津)、49.0%(久保木)、74.7%(桧原)、73.0%(本誌飯田)。この18レースに関する限り、柏木氏の予想のARが77.6%で最高で、低い人は50%前後ということが分かります。もちろんこの傾向が、ずっと続くのか、それともタマタマだったのかは、レース数を増やさないと分からない。でも、素直な感想は、プロの予想は結構すばらしいというものです。最初の回で、競馬ファンの予想(オッズ)のARは約68%弱と書きました。その結果は何万レースでの予想の結果だったのですが、その数字と比較してもスバラシイ。
そこで、今回の課題です。
(1)前回入力した18レースのデータに、オッズのデータを追加する。
(2)オッズのARを計算し、上記の6名の予想のARとの比較を行う。
(3)6名の予想とオッズを用いて、ARがもっとも高い予想の作成を行う。
ここで、(3)の課題に対するヒントです。いろいろな予想があった場合、ひとつひとつの予想にはどうしてもバラつきがある。あるレースですばらしい予想をしても、別のレースでは完全に外したりして、全レースでなかなかピタリとあてるのは難しい。では、このバラつきを減らすにはどうすればいいのかというと、「単に平均をとればいい」というのが「集合知」でよく知られた事実です。そうすれば、ある馬に対し、ある予想ば過大評価、ある予想は過小評価しても、その平均をとると、過大評価と過小評価が相殺して、適正な評価が得られるわけです。
実際には、ある数値に対する個々人の評価は、正規分布のような左右対称に分布するわけではない。むしろ対数正規のような、過大評価側にテールが伸びている。つまり、むちゃくちゃ大きな値を予想する人が出てしまう。この場合、単純な平均(算術平均)では、バラつきをキャンセルできず、どうしてもバイアスが残ってしまう。J.Lorenz(2011,PNAS)の実験では、スイスの平均人口密度やスイスーイタリアの国境の長さなど6問について12人の被験者に予想してもらうという実験を行ったのですが、その結果を見ると、算術平均ではひどい結果でした。人口密度は実際は184名なのに、算術平均は2644名。こうした場合は、算術平均の代わりに幾何平均を使うのがいい。つまり、データの対数の平均をとるわけです。すると、対数正規分布は正規分布に代わり、左右対称になるので、あとは算術平均し、指数関数にいれて戻してやる。これは幾何平均と同じこと。その結果は132名で、ムチャクチャ大きな予想をした人の影響をうまく消して、真の値184名に結構近づいていることが分かります。
このように、問題によっては算術平均ではなく幾何平均を用いたり、いろいろ工夫する必要があるのですが、試しに「予想の平均」を計算して、それを用いてARを計算してみました。ある馬に対し、本命1、対抗2といった数値が6名分あるので、それを全部足して6で割って平均を計算。そして、数値の小さい順に馬を並べ替えて、ROCカーブを描き、AUROCを計算してARを求める。結果が次の図です。

すると、ARは81.4%となり、柏木氏の77.6%に勝っていることが分かります。ここで課題(3)に戻ると、本命=1、対抗=2と数値を決めていますが、この数値を動かす。また、オッズの数値も適当に変換し(定数倍)、それらの数値を用いてARが一番大きくなる「方程式」を導くというものです。
各自担当レースのオッズをデータに追加し、来週の土曜日に課題の結果を持ってくること。
課題のデータは、全部で18レース分です。
(本命1、対抗2、 単穴3、二重△4、△5、その他6としています。勝馬1、負け馬0。)
http://dl.dropbox.com/u/13984080/20120303_kadai.d
このデータを用いて、6名の予想者それぞれのARを計算するというものでした。結果は、6名の予想者それぞれの予想のARは、77.6%(柏木)、50.7%(宮崎)、60.4%(黒津)、49.0%(久保木)、74.7%(桧原)、73.0%(本誌飯田)。この18レースに関する限り、柏木氏の予想のARが77.6%で最高で、低い人は50%前後ということが分かります。もちろんこの傾向が、ずっと続くのか、それともタマタマだったのかは、レース数を増やさないと分からない。でも、素直な感想は、プロの予想は結構すばらしいというものです。最初の回で、競馬ファンの予想(オッズ)のARは約68%弱と書きました。その結果は何万レースでの予想の結果だったのですが、その数字と比較してもスバラシイ。
そこで、今回の課題です。
(1)前回入力した18レースのデータに、オッズのデータを追加する。
(2)オッズのARを計算し、上記の6名の予想のARとの比較を行う。
(3)6名の予想とオッズを用いて、ARがもっとも高い予想の作成を行う。
ここで、(3)の課題に対するヒントです。いろいろな予想があった場合、ひとつひとつの予想にはどうしてもバラつきがある。あるレースですばらしい予想をしても、別のレースでは完全に外したりして、全レースでなかなかピタリとあてるのは難しい。では、このバラつきを減らすにはどうすればいいのかというと、「単に平均をとればいい」というのが「集合知」でよく知られた事実です。そうすれば、ある馬に対し、ある予想ば過大評価、ある予想は過小評価しても、その平均をとると、過大評価と過小評価が相殺して、適正な評価が得られるわけです。
実際には、ある数値に対する個々人の評価は、正規分布のような左右対称に分布するわけではない。むしろ対数正規のような、過大評価側にテールが伸びている。つまり、むちゃくちゃ大きな値を予想する人が出てしまう。この場合、単純な平均(算術平均)では、バラつきをキャンセルできず、どうしてもバイアスが残ってしまう。J.Lorenz(2011,PNAS)の実験では、スイスの平均人口密度やスイスーイタリアの国境の長さなど6問について12人の被験者に予想してもらうという実験を行ったのですが、その結果を見ると、算術平均ではひどい結果でした。人口密度は実際は184名なのに、算術平均は2644名。こうした場合は、算術平均の代わりに幾何平均を使うのがいい。つまり、データの対数の平均をとるわけです。すると、対数正規分布は正規分布に代わり、左右対称になるので、あとは算術平均し、指数関数にいれて戻してやる。これは幾何平均と同じこと。その結果は132名で、ムチャクチャ大きな予想をした人の影響をうまく消して、真の値184名に結構近づいていることが分かります。
このように、問題によっては算術平均ではなく幾何平均を用いたり、いろいろ工夫する必要があるのですが、試しに「予想の平均」を計算して、それを用いてARを計算してみました。ある馬に対し、本命1、対抗2といった数値が6名分あるので、それを全部足して6で割って平均を計算。そして、数値の小さい順に馬を並べ替えて、ROCカーブを描き、AUROCを計算してARを求める。結果が次の図です。

各自担当レースのオッズをデータに追加し、来週の土曜日に課題の結果を持ってくること。
2012年3月3日土曜日
競馬予想の精度
これから競馬予想を作っていくわけですが、その目標は「勝ち馬をあてる」ことにあります。ただ、競馬でもうけるには、「この馬が勝ちそうだ」という予想では不十分で、その勝つ確率まで分からないとダメ。勝ちそうだという馬の「真の勝率」が3割だとして、その馬のオッズが3.4より低ければ、勝率とオッズの掛け算の結果は1以下となり、期待される返金額は掛けたお金以下、期待リターンはマイナスとなります。むしろ、勝率が1%であっても、その馬のオッズが100倍を超えているなら、期待される返金額は掛けたお金を上回り、期待リターンはプラスとなります。もっとも、勝率1%の馬か勝つことは100回に1回の比率でしかなく、そうした稀なチャンスを待つことはなかなか難しい。100円掛けるとしても100回待つには1万円は必要です。また100回待てば必ず1回勝つわけではなく、場合によっては200回やそれ以上待たないと勝たないかもしれない。そもそも「勝率は1%」と正確に評価することは難しい。
このように、競馬で儲けるには、勝馬予想だけでなく、その勝率まで必要です。しかし、いきなり勝率まで予想するのは難しいので、まずは勝ち馬予想の精度から始めることにしましょう。私の手元には2010年3月28日の「日刊競馬」というのがあり、1面は第40回高円宮記念(GI)の予想、解説となっています。4歳以上のオープンで、18頭が出走。過去八走の成績と、6人の予想印、見解と情報、スタッフ予想、能力指数、専門誌8社の予想などなど。非常にモリだくさん。ここで、予想印とは、◎や○、△、▲で示される予想のこと。◎が本命、○が対抗、▲が単穴で、△が連下と呼ばれ、この順番で強さが示されます。つまり、一番強いのが◎の本命、2番目に強いのが○という感じです。
 では、この予想印はどれほど正しいのでしょうか。単純に考えれば、◎の馬の勝ち数、○の馬の勝ち数などを求め、 それらが大きいほど、また△よりは▲、▲よりは○、○よりは◎という順番も加味した勝ち数が多いほどいい。例えば、10レース中「◎で5回1着で他は外れ」のほうが、「○で5回勝ち他は外れ」よりもすぐれた予想ということです。このように、印には◎が1番、○が2番、▲は3番、△は4番といった順番があり、同じ勝数を予想しても順番の高い印で勝ち数が多いほうが価値があるわけです。一方、馬にはレースでの着順という情報があるのですが、ここでは勝馬予想を考えているので、勝った、負けたというという二値の情報とし、勝ちを1、負けを0とします。すると、予想の精度は高い順番の印での1の数が多ければ高いことになります。では、その精度を数値化するのはどうすればよいのでしょうか。ここでは、AUROC(Area under ROC curve)と呼ばれるROCカーブの下側(under)の面積(area)から計算されるAR(Accuracy Ratio)を紹介します。
では、この予想印はどれほど正しいのでしょうか。単純に考えれば、◎の馬の勝ち数、○の馬の勝ち数などを求め、 それらが大きいほど、また△よりは▲、▲よりは○、○よりは◎という順番も加味した勝ち数が多いほどいい。例えば、10レース中「◎で5回1着で他は外れ」のほうが、「○で5回勝ち他は外れ」よりもすぐれた予想ということです。このように、印には◎が1番、○が2番、▲は3番、△は4番といった順番があり、同じ勝数を予想しても順番の高い印で勝ち数が多いほうが価値があるわけです。一方、馬にはレースでの着順という情報があるのですが、ここでは勝馬予想を考えているので、勝った、負けたというという二値の情報とし、勝ちを1、負けを0とします。すると、予想の精度は高い順番の印での1の数が多ければ高いことになります。では、その精度を数値化するのはどうすればよいのでしょうか。ここでは、AUROC(Area under ROC curve)と呼ばれるROCカーブの下側(under)の面積(area)から計算されるAR(Accuracy Ratio)を紹介します。
図を見てください。全部で3レースあり、各3頭出走し、全9頭の馬にそれぞれ本命◎、対抗○、単穴▲の印がついています。また、レースの結果の着順も示してあります(図の上段)。この情報を、中段に示された情報にまとめます。◎、○、▲の順番に馬を並べます。印の右下の数字がレース番号)が示されています。そして、印の下に、レース結果を書きます。馬が勝てば1、負ければ0とします。下段はROCカーブを示しています。中段の情報から下段のROCカーブを描くのには、次のようにします。今、◎の馬が3レース分で3頭いて、そのうち二頭が勝ち、1頭が負けたので、原点(0,0)からx軸に1、y軸に2進み、(1,2)と(0,0)を結びます。次に、○の馬3頭のうち、1頭が勝ち、2頭が負けなので、x軸に2、y軸に1すすんで、(3,3)に到達し、(1,2)と結びます。最後、▲の馬3頭は頭も勝っていないので、x軸に3、y軸に0すすんで、(6,3)に到達し、(3,3)と結びます。こうして、原点(0,0)と(6,3)を結ぶ折れ線が描かれましたが、これをROCカーブ(緑)です。このROCカーブの下側の面積AUROCは、横6縦3の長方形の面積18からカーブの上側部分の面積3をひいて15となります。
この面積と予想精度はどのような関係にあるのでしょう?まず、予想が完璧で本命馬◎がすべて勝った場合、ROCカーブは原点と(0,3)と(6,3)を結ぶ折れ線(赤点線)になります。この時の面積は18で、実際の予想での面積15より大きくなっています。逆に最悪の予想の場合、つまり本命、対抗が全敗し、▲が3頭とも勝った場合、ROCカーブは原点と(6,0)と(6,3)を結んだも(赤一点鎖線)のとなり、ROCカーブの面積は0となります。予想とレース結果に関係がない場合、◎、○、▲が一勝ずつとなりますが、このときのROCカーブは(0,0)と(6,3)を結んだ対角線(黄)となり、面積は18の半分の9となります。ARは、この予想が結果と全く関係がない場合の面積を基準とし、完全な場合に1となるように定義されています。上の予想の場合、予想のROCカーブの面積は15だったので、基準の面積9を引いて6とし、18(完璧)-9(基準)で割ることにより、ARは6/9となります。
では、実際の競馬予想の精度はどの程度なのでしょうか?今回の課題は、日刊競馬にある18レースの競馬予想の精度を求めることです。
①上図の例をデータファイルにし、読み込んでAUROC、ARを計算する。
②競馬新聞の予想をデータファイルにする。レース結果はYahoo!競馬で取得する。
③①のプログラムをもとに、②のデータで6人(柏木、宮崎、黒津、久保木、桧原、本誌飯田)の予想の精度(AR)を求める。
ヒント:次のプログラムを参考に
http://dl.dropbox.com/u/13984080/AR.c
図の例のデータファイルは
http://dl.dropbox.com/u/13984080/20120303.d
にあります。 データはCSV形式。レース番号、馬番号、徴の番号、着順です。
プログラムをコンパイルし、
./a.out 20120303.d ROC.d
とすると、ROCカーブのデータを作成し、ファイルROC.dに書き込みます。
gnuplotでプロットしてください。
gnuplotを起動し、
plot ROC.d w l lw 4
で、ROCカーブを描いてくれます。
課題のデータ入力をまとめたのでアップします。全部で18レース分です。
(本命1、対抗2、 単穴3、二重△4、△5、その他6としています。勝馬1、負け馬0。)
http://dl.dropbox.com/u/13984080/20120303_kadai.d
このデータを用いて6名の予想者それぞれのARを計算してください。
また、この情報をどのように活用すれば、よりARが高くなるか考えてください。
このように、競馬で儲けるには、勝馬予想だけでなく、その勝率まで必要です。しかし、いきなり勝率まで予想するのは難しいので、まずは勝ち馬予想の精度から始めることにしましょう。私の手元には2010年3月28日の「日刊競馬」というのがあり、1面は第40回高円宮記念(GI)の予想、解説となっています。4歳以上のオープンで、18頭が出走。過去八走の成績と、6人の予想印、見解と情報、スタッフ予想、能力指数、専門誌8社の予想などなど。非常にモリだくさん。ここで、予想印とは、◎や○、△、▲で示される予想のこと。◎が本命、○が対抗、▲が単穴で、△が連下と呼ばれ、この順番で強さが示されます。つまり、一番強いのが◎の本命、2番目に強いのが○という感じです。

図を見てください。全部で3レースあり、各3頭出走し、全9頭の馬にそれぞれ本命◎、対抗○、単穴▲の印がついています。また、レースの結果の着順も示してあります(図の上段)。この情報を、中段に示された情報にまとめます。◎、○、▲の順番に馬を並べます。印の右下の数字がレース番号)が示されています。そして、印の下に、レース結果を書きます。馬が勝てば1、負ければ0とします。下段はROCカーブを示しています。中段の情報から下段のROCカーブを描くのには、次のようにします。今、◎の馬が3レース分で3頭いて、そのうち二頭が勝ち、1頭が負けたので、原点(0,0)からx軸に1、y軸に2進み、(1,2)と(0,0)を結びます。次に、○の馬3頭のうち、1頭が勝ち、2頭が負けなので、x軸に2、y軸に1すすんで、(3,3)に到達し、(1,2)と結びます。最後、▲の馬3頭は頭も勝っていないので、x軸に3、y軸に0すすんで、(6,3)に到達し、(3,3)と結びます。こうして、原点(0,0)と(6,3)を結ぶ折れ線が描かれましたが、これをROCカーブ(緑)です。このROCカーブの下側の面積AUROCは、横6縦3の長方形の面積18からカーブの上側部分の面積3をひいて15となります。
この面積と予想精度はどのような関係にあるのでしょう?まず、予想が完璧で本命馬◎がすべて勝った場合、ROCカーブは原点と(0,3)と(6,3)を結ぶ折れ線(赤点線)になります。この時の面積は18で、実際の予想での面積15より大きくなっています。逆に最悪の予想の場合、つまり本命、対抗が全敗し、▲が3頭とも勝った場合、ROCカーブは原点と(6,0)と(6,3)を結んだも(赤一点鎖線)のとなり、ROCカーブの面積は0となります。予想とレース結果に関係がない場合、◎、○、▲が一勝ずつとなりますが、このときのROCカーブは(0,0)と(6,3)を結んだ対角線(黄)となり、面積は18の半分の9となります。ARは、この予想が結果と全く関係がない場合の面積を基準とし、完全な場合に1となるように定義されています。上の予想の場合、予想のROCカーブの面積は15だったので、基準の面積9を引いて6とし、18(完璧)-9(基準)で割ることにより、ARは6/9となります。
では、実際の競馬予想の精度はどの程度なのでしょうか?今回の課題は、日刊競馬にある18レースの競馬予想の精度を求めることです。
①上図の例をデータファイルにし、読み込んでAUROC、ARを計算する。
②競馬新聞の予想をデータファイルにする。レース結果はYahoo!競馬で取得する。
③①のプログラムをもとに、②のデータで6人(柏木、宮崎、黒津、久保木、桧原、本誌飯田)の予想の精度(AR)を求める。
ヒント:次のプログラムを参考に
http://dl.dropbox.com/u/13984080/AR.c
図の例のデータファイルは
http://dl.dropbox.com/u/13984080/20120303.d
にあります。 データはCSV形式。レース番号、馬番号、徴の番号、着順です。
プログラムをコンパイルし、
./a.out 20120303.d ROC.d
とすると、ROCカーブのデータを作成し、ファイルROC.dに書き込みます。
gnuplotでプロットしてください。
gnuplotを起動し、
plot ROC.d w l lw 4
で、ROCカーブを描いてくれます。
課題のデータ入力をまとめたのでアップします。全部で18レース分です。
(本命1、対抗2、 単穴3、二重△4、△5、その他6としています。勝馬1、負け馬0。)
http://dl.dropbox.com/u/13984080/20120303_kadai.d
このデータを用いて6名の予想者それぞれのARを計算してください。
また、この情報をどのように活用すれば、よりARが高くなるか考えてください。
2012年3月2日金曜日
競馬予想の作り方:はじめに
明日(2011年3月3日)から、平成24年度の卒業研究が始まるので、その実習テーマとして「競馬予想の作り方」をとりあげます。
内容は、以前、JWEIN2010の講演「競馬予想とは何か?」でも扱ったロジットモデルによって、単勝馬券の適正オッズを計算するというもの。その仕組みや、評価方法を解説しながら、競馬ファンによる予想(レースでの最終オッズ)の精度にどの程度迫れるのか、挑戦してみようと考えています。
平成22年度の入江君の卒業研究「競馬予想と集団知」では、スポーツ新聞の競馬予想の情報を加味してロジットモデルを最適化し、競馬ファンの予想(AR=Accuracy Ratio=67.8%)にほんのわずか(AR=65.4%)のところまで迫ることができました。さらに、競馬ファンのオッズの情報まで加えて、最適化すると、オッズよりほんのわずか高い精度(0.2%)で予想が作れそうだということも。
図がそのときの結果です。ロジット単独だと、ARは56.3%で、JRA-VANの順位予想(AR=50.5%)をファクターに入れて最適化すると58.9%。それにスポーツ新聞の予想もいれて最適化すると65.4%まで上がり、単勝馬券の最終得票率もいれて最適化したモデルのARは68.0%となり、競馬ファンの予想のARを0.2%上回っています。ただ、「+0.2%」は、あまりにも小さく、誤差の範囲内ともとれるレベル。また、最終の得票率の情報は実際のレースで入手することは無理なので、競馬ファンの予想に勝ったとは言えません(実際には、レース直前に大量の投票が行われても、予想精度そのものは大して変化しないので、出走30分前の得票率で十分のようですが)。
今回は、
①ロジット単独でスポーツ新聞よりも精度の高い予想を行うこと。
②スポーツ新聞の予想を加味したときに、競馬ファンの予想精度を上回ること
の二つを目標としています。
これらの目標を目指し、かつ卒業研究の実習をかねて、平成24年度の1年間、1週間に1度(土曜日)、競馬予想の課題とその結果についてこのブログに掲載していく予定です。
 どこまで続くかな分かりませんが、頑張れるだけやってみようと思います。何分、私は馬券を買ったこともなく、過去の文献などをもとにロジットモデルを作っているだけなので、どのようなファクターをモデルにいれるのがよいのかについてのアイデアがあまりありません。経験豊富な方からのアドバイスも歓迎します。よろしくお願いします。
どこまで続くかな分かりませんが、頑張れるだけやってみようと思います。何分、私は馬券を買ったこともなく、過去の文献などをもとにロジットモデルを作っているだけなので、どのようなファクターをモデルにいれるのがよいのかについてのアイデアがあまりありません。経験豊富な方からのアドバイスも歓迎します。よろしくお願いします。
内容は、以前、JWEIN2010の講演「競馬予想とは何か?」でも扱ったロジットモデルによって、単勝馬券の適正オッズを計算するというもの。その仕組みや、評価方法を解説しながら、競馬ファンによる予想(レースでの最終オッズ)の精度にどの程度迫れるのか、挑戦してみようと考えています。
平成22年度の入江君の卒業研究「競馬予想と集団知」では、スポーツ新聞の競馬予想の情報を加味してロジットモデルを最適化し、競馬ファンの予想(AR=Accuracy Ratio=67.8%)にほんのわずか(AR=65.4%)のところまで迫ることができました。さらに、競馬ファンのオッズの情報まで加えて、最適化すると、オッズよりほんのわずか高い精度(0.2%)で予想が作れそうだということも。
図がそのときの結果です。ロジット単独だと、ARは56.3%で、JRA-VANの順位予想(AR=50.5%)をファクターに入れて最適化すると58.9%。それにスポーツ新聞の予想もいれて最適化すると65.4%まで上がり、単勝馬券の最終得票率もいれて最適化したモデルのARは68.0%となり、競馬ファンの予想のARを0.2%上回っています。ただ、「+0.2%」は、あまりにも小さく、誤差の範囲内ともとれるレベル。また、最終の得票率の情報は実際のレースで入手することは無理なので、競馬ファンの予想に勝ったとは言えません(実際には、レース直前に大量の投票が行われても、予想精度そのものは大して変化しないので、出走30分前の得票率で十分のようですが)。
今回は、
①ロジット単独でスポーツ新聞よりも精度の高い予想を行うこと。
②スポーツ新聞の予想を加味したときに、競馬ファンの予想精度を上回ること
の二つを目標としています。
これらの目標を目指し、かつ卒業研究の実習をかねて、平成24年度の1年間、1週間に1度(土曜日)、競馬予想の課題とその結果についてこのブログに掲載していく予定です。

登録:
投稿 (Atom)